
Background
The objective of a Vulnerability Management program is to measure and improve the security of an enterprise organisation, and by automating processes to minimise cost.
The resources that fulfil the security objective typically span multiple teams, are using multiple tools, have different objectives, and run to different targets.
The team responsible for vulnerability scanning typically focus on a scanning technology; the people responsible for patching / remediation typically work from ticketing systems. This mismatch often makes matters worse.
To state the obvious, the act of getting a list of vulnerabilities does not improve security. It is only when actions are taken to remediate (or mitigate) those vulnerabilities, that security improves.
It is therefore key that all of the teams come together, with automated tools, agreed processes and clear roles / responsibilities. This all needs to fit within agreed SLAs.
The following article is based upon our experience of working with large multi-national organisations, helping them to automate and improve their vulnerability management processes.
We have also a blog that would be good to read together with this blog, on our 8 Best Practice Steps For Effective Vulnerability lifecycle Management if you want more information on the detailed processes that we will address in this blog.
The Vision
It is probably worth stating with the “vision” of where most organisations want to be, and then filling in the detail of how to get there.
In the diagram below, the objective is that all of the steps are automatic, followed by automating processes.
The actual work gets carried out on the “remediate” stage, this is where someone has a ticket to do something and they do it. The rest should “just happen”.
In the real world, people need to watch the process and ensure that people are doing what they should be, but everything else is automated. No emails, no Excel files, no being chased on the phone, it should just flow in one continuous process.
Automating processes is key
If you have people sending emails with attachments, they can make decisions on what to pass to who, what time scales are given, and so on.
When it comes to Vulnerability Management if you want automation, and to standardise things, then you need to have clearly defined rules on how things happen. This is where a clear and simple process flow to follow has a lot of value.
The process should define how you measure the severity of a security issue, how it gets fixed and in what time frame, along with the clear interactions between the various teams.
The rest of this article will focus on the elements of automating processes, and suggestions on what to do at each step. When you have a fully agreed and adopted process, you are able to develop automation.
At the very end of this piece, we will also make some tool recommendations that are specifically built for this process.
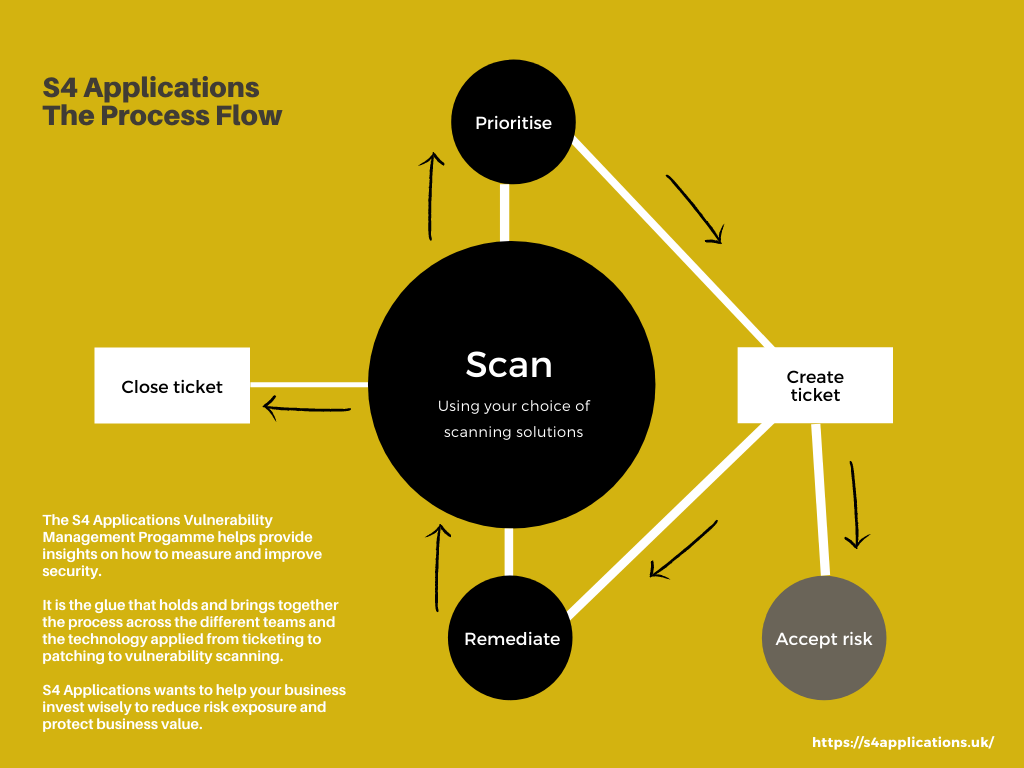
It is probably worth talking through the above diagram, it makes most sense to start with the “Scan” stage.
Scan
Here you get a source of data about the security issues that relate to an issue. The easiest source is a vulnerability scanner which says “machine X has CVE Y”. The same logic applies to applications, to containers with security issues, to miss-configured AWS buckets etc.
As long as you have scan data that tells you “Asset X has problem Y” then you can move onto the next stage. Adding in extra information is always advantageous, things like how to “fix Y”, but that data is not strictly necessary.
Prioritise
Working out the importance of the security issue is itself a complex piece of work, and we have a separate blog on in.
Rather than repeating that, assume that you can take many pieces of different information about servers, applications, locations and properties of the security issue, etc. and come up with a number, say in the range 0 (don’t worry) – 100 (panic).
Once the data has been prioritised, it should be moved to the next stage.
Create Ticket
Now that we have a set of prioritised security issues, we need to create tickets to get them fixed.
Most companies have a preferred ticketing system, that the users are already familiar with, so you need tight integration into the incumbent systems.
Creating tickets for all security issues isn’t viable or sensible, so you are going to want to apply a filter. We would suggest that you want to create tickets for issues that have a priority above a given level deemed as being serious.
Some experts would suggest that you should only create tickets for items that have a fix available, in our experience it makes sense to have the ticket, and then deal with the absence of a fix as part of the risk process.
When tickets are created, they typically want to be aggregated, often by solution. This typically varies by data source.
For something like a network scan, from say Tenable or Qualys, then grouping by the solution makes perfect sense. The most obvious example here would be a Windows patch Tuesday; that may fix 100 CVEs, but is only 1 patch.
For DAST tools with Web applications, it is common to group things by web page, because this is the way that the developers work. For SAST tools, grouping by software modules makes sense; again, because this is how the developers work.
Once those tickets have been created, they end up going one of two different routes.
Remediate
Here someone with the ability to remediate the issue is assigned the ticket, and a time window to perform the task.
Once done the ticket is tagged as “Remediated pending verification”.
The act of doing this could trigger a re-scan of the particular issue, or the ticket could wait until the next scheduled scan.
This is ultimately the most important step, as it is this that actually makes the difference. Rather than “Vulnerability Management” the process should really be called “Vulnerability Remediation Management”.
Accept Risk
Not all security issues can be fixed. There are many reasons for this including:
- No patch available
- Applying a patch would take a system to an unsupported level
- Stability windows imposed around critical business times (say Christmas for a retailer)
If an item is not going to be fixed, then a separate risk acceptance process has to be started, where the business reviews the issues, associated risks and any mitigations available. Items can then be added onto a risk register and reviewed regularly based on severity.
Scan
This is the same step as above, but this time when the scan data arrives, it needs to be compared to the previous data set and some decisions made.
If the issue still exists then any tickets need moving back to the remediation teams with an appropriate status that needs more attention.
Close Ticket
In the event that a security issue is no-longer in the data set, then that element of the aggregate ticket can be closed. If everything on the ticket has been closed then the entire ticket can be closed.
The logic here is a little more complex because a “quick scan” may not check everything, so the omission of a security issue could be because it was fixed, or could be because it wasn’t checked for. This needs to be taken account of and documented in the user guidelines.
Prioritise
Jump to the Prioritise stage above.
Thoughts on the automating process …
As you can see from the above, apart from acting upon the ticket everything else can be automated in vulnerability management.
The data flow from start to end doesn’t require human interaction. Yes, there are some metrics to adjust, like the priority at which a ticket gets created, or how long the remediation team have to fix a security issue with a 90+ score, but it can all be automated.
To have good Vulnerability Management automation you need to pass all of the data from one process step to the next.
As we are talking very large volumes of data, it makes sense to have a central database with everything in it, and then pass references around.
Nearly all of the tools that you want to connect to have API access (see the article on Integration for more information) so you can automatically update that database as the sources change.
The above steps are a simplified model, we have a separate blog on the full 8 step model that we recommend.
Bigger than it initially looks …
This article about Automation is part of a 4-article series all of which look at different parts of the same problem. Here we have focused on one area, and neatly skipped over some other, rather complex issues.
We see the 4 key pillars to a complete vulnerability solution encompassing the following high-level functionality:
Prioritisation of issues – No organisation, not even the best, ever gets rid of all their security issues, but they do make an effort to create a complete list of them, and then fix the worst ones. And there is the challenge, what are the “worst ones”? This sounds simple, but is deceptively hard.
Integration of data – Saying “connect to my DAST tool and extract the data” is much easier to write than to implement, as is aligning data from DAST, SAST and network scans into a single, browsable data set that allows you to navigate from application, to server to vulnerability and so on.
Visualisation and dashboard reporting – As much as things are automated, people don’t always do what you expect in the way you expect; for this reason, you need reports, dashboards and other ways of understanding what has happened to get you where you are now, what is happening at that point in time, and where you need to go in the future to achieve your goals and objectives
Automation – discussed in this blog
You will find that we discuss all 4 items in the article on Vulnerability Management Program.
Security vendors don’t help
The security product vendors all have a reasonable idea of the above and are all building a suite of tools to address parts of the problem. The issue is that most vendors have one good tool and a bunch of mediocre tools that tag along.
If I look at Qualys (I am not picking on them, insert Tenable, Rapid7 etc., they are all the same), their network scanning tool is genuinely market-leading. The other 20+ that they have range from “ok” to “hmm, not bad”. They exist together to meet a sales objective of “we need more products to sell to our existing customers”.
Be wary of vendor lock-in business models.
Several years ago, software vendors would sell a perpetual license to their software; this was expensive in year 1, but less so in year 2+. This created a degree of vendor lock-in, because if you wanted to move, then you had to pay that big up-front fee again.
The vendors then worked out that they could make more money by selling annual subscriptions (which is where everyone now is). This has the advantage that, as a user, you can switch if a vendor falls behind the market or gets too aggressive with their pricing.
This burned a number of vendors, so they now look for other ways to generate lock-in. One of those is selling a set of loosely connected, mediocre tools. That makes it much harder to get rid of them all. Also, should you decide to remove one tool, they may put the pricing up on the others as a disincentive.
We generally recommend buying best-of-breed technologies and reviewing the situation every 2 to 3 years to ensure that you have the best technology at the best price.
Next steps
A planned and pragmatic vulnerability management programme will constantly review an organisation’s current status quo. Providing a roadmap on how to measure and improve security in your organisation.
S4 Applications wants to help your business invest wisely to reduce risk exposure and protect business value. Contact us to guide you through an effective Vulnerability Management Programme.
What is security maturity and how can S4 Applications help you enhance your security posture? Read our blog: Assess your security Posture with our Security Maturity Model.